当我们交叉使用字节流和字符流时,除非我们了解字符集的基础知识,否则事情可能会变得混乱。许多关于字符编码的教程和帖子都是理论上的,很少有真实的例子。在这篇文章中,我们试图用简单易懂的例子来揭开Unicode的神秘面纱。
Java中的Unicode 编码(Encode)和解码(Decode) 在深入研究Unicode之前,首先让我们了解术语-编码和解码。假设我们捕获了mpeg格式的视频,摄像机中的编码器将像素编码成字节,当回放时,解码器将字节转换回像素。当我们创建一个文本文件时,也会出现类似的过程。例如,当在文本编辑器中键入字母H时,操作系统将字符串编码为字节0x 48并将其传递给编辑器。编辑器将字节保存在其缓冲区中,并将其传递给窗口系统,窗口系统将字节0x 48解码并显示为H。当文件被保存时,0x 48进入文件。
简而言之,编码器将像素、音频流或字符等项转换为二进制字节,解码器将字节重新转换回原始形式。
Java字符串的编码和解码 让我们继续用Java编码一些字符串:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class StringEncoder { public static void main (String[] args) { String str = "Hello" ; byte [] bytes = str.getBytes(StandardCharsets.US_ASCII); printBytes(bytes); } public static void printBytes (byte [] a) { StringBuilder sb = new StringBuilder (); for (byte b : a) { sb.append(String.format("x%02x " , b)); } System.out.println(sb); } }
String.getBytes() 方法使用US_ASCII字符集将字符串编码为字节(二进制), printBytes() 方法以十六进制格式输出字节。十六进制输出 0x48 0x65 0x6c 0x6c 0x6f 是ASCII格式的字符串 Hello 的二进制。
接下来,让我们看看如何将字节解码为字符串。
1 2 3 4 5 6 7 8 public class StringDecoder { public static void main (String[] args) { byte [] bytes = {0x48 , 0x65 , 0x6c , 0x6c , 0x6f }; String str = new String (bytes, StandardCharsets.US_ASCII); System.out.println(str); } }
在这里,我们将填充有 0x48 0x65 0x6c 0x6c 0x6f 的字节数组解码为新字符串。String类使用US_ASCII字符集解码字节,显示为 Hello 。
我们可以省略 new String(bytes) 和 str.getBytes() 中的 StandardCharsets.US_ASCII 参数。结果将与Java的默认字符集相同,即UTF-8,其使用与US_ASCII相同的英文字母十六进制值。
ASCII编码方案非常简单,每个字符都映射到一个字节,例如,H编码为0x 48,e编码为0x 65等。它可以处理英文字符集,数字和控制字符,如退格键,回车等,但没有太多的西方或亚洲语言字符等。
使用中文编码
让我们编码和解码单个中文字符“你”:
1 2 3 4 5 6 7 8 String str = "你" ; byte [] bytes = str.getBytes(StandardCharsets.UTF_8); printBytes(bytes); String decodedStr = new String (bytes, StandardCharsets.UTF_8); System.out.println(decodedStr);
用UTF-8字符集编码字符你返回一个3字节的数组 xe4 xbd xa0 ,解码时返回“你”。
让我们对另一个标准字符集UTF_16做同样的事情。
1 2 3 4 5 6 7 8 String str = "你" ;byte [] bytes = str.getBytes(StandardCharsets.UTF_16);printBytes(bytes); String decodedStr = new String (bytes, StandardCharsets.UTF_16);System.out.println(decodedStr);
字符集UTF_16将你编码为4个字节- xfe xff x4f x60 ,而UTF_8使用3个字节管理它。
这时,尝试用US_ASCII编码“你”,它返回一个字节 x3f ,为什么呢?这是因为ASCII是单字节编码方案,不能处理除英文字母以外的字符。
Unicode简介 Unicode是编码字符集(或简称字符集),能够代表大多数书写系统。最新版本的Unicode包含约138 000个字符,涵盖150种现代和历史语言和文字,以及符号集和表情等。下表显示了来自不同语言的一些字符如何在Unicode中表示。
Character Code Point 代码点 UTF_8 UTF_16 Language a U+0061 61 00 61 English Z U+005A 5a 00 5a English â U+00E2 c3 a2 00 e2 Latin Δ U+0394 ce 94 03 94 Latin ع U+0639 d8 b9 06 39 Arabic 你 U+4F60 e4 bd a0 4f 60 Chinese 好 U+597D e5 a5 bd 59 7d 59 7 d Chinese ಡ U+0CA1 e0 b2 a1 0c a1 Kannada ತ U+0CA4 e0 b2 a4 0c a4 Kannada
每个字符或符号由唯一的代码点表示。Unicode有1 112 064个编码点,其中约138 000个是目前定义的。Unicode码位表示为U+xxxx,其中U表示Unicode。 String.codePointAt(int index) 方法返回字符的代码点。
1 2 3 4 5 String str = "你" ;int codePoint = str.codePointAt(0 ); System.out.format("U+%04X" , codePoint);
一个字符集可以有一个或多个编码方案,Unicode有多种编码方案,如UTF_8、UTF_16、UTF_16LE和UTF_16BE,它们将代码点映射到字节。
UTF-8 UTF-8(8位Unicode转换格式)是一种可变宽度字符编码,能够使用一到四个8位字节对所有有效的Unicode代码点进行编码。在上表中,我们可以看到UTF-8编码字节的长度从1到3字节不等。大多数网页使用UTF-8。
Unicode的前128个字符与ASCII一一对应,使用具有与ASCII相同的二进制值的单个字节进行编码。有效的ASCII文本也是有效的UTF-8编码的Unicode。
UTF-16 UTF-16(16位Unicode转换格式)是另一种能够处理Unicode字符集所有字符的编码方案。编码是可变长度的,因为代码点是用一个或两个16位代码单元(即最小2字节和最大4字节)编码的。
许多系统,如Windows、Java和JavaScript,在内部使用UTF-16。它也经常用于纯文本和Windows上的文字处理数据文件,但很少用于Unix/Linux或macOS上的文件。
Java内部使用UTF-16。从Java 9开始,为了减少String对象占用的内存,它根据字符串的内容使用ISO-8859-1/Latin-1(每个字符一个字节)或UTF-16(每个字符两个字节)。JEPS 254 。
但是,不要将内部字符集与Java默认字符集(UTF-8)混淆。例如,String以UTF-16的形式存在于堆内存中,但是方法 String.getBytes() 返回编码为UTF-8的字节,默认的字符集。
您可以使用CharInfo.java来显示字符串的字符详细信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import java.nio.charset.Charset;import java.nio.charset.StandardCharsets;import java.util.Scanner;public class CharInfo { public static void main (String[] args) throws Exception { displayCharInfo("a Z â Δ 你 好 ಡ ತ ع" ); } public static void displayCharInfo (String str) { System.out.format("%12s\t%-10s\t%-10s\t%-20s%n" , "Character" , "Codepoint" , "UTF_8" , "UTF_16" ); try (Scanner s = new Scanner (str)) { while (s.hasNext()) { String ch = s.next(); String codepoint = getCodepoint(ch); byte [] u8 = encode(ch, StandardCharsets.UTF_8); String u8Hex = bytesToHex(u8); byte [] u16 = encode(ch, StandardCharsets.UTF_16); String u16Hex = bytesToHex(u16); System.out.format("\t%s\t%-10s\t%-10s\t%-20s%n" , ch, codepoint, u8Hex, u16Hex); } } } private static byte [] encode(String data, Charset charset) { return data.getBytes(charset); } private static String getCodepoint (String ch) { return String.format("U+%04X" , ch.codePointAt(0 )); } private static String bytesToHex (byte [] bytes) { StringBuilder sb = new StringBuilder (); for (byte b : bytes) { sb.append(String.format("%02x " , b)); } return sb.toString(); } }
总结如下:
字符集是字符的集合。数字、字母和汉字是字符集的示例。 编码字符集是每个字符都有一个分配的 int 值的字符集。 Unicode、US-ASCII 和 ISO-8859-1 是编码字符集的示例。 代码点是分配给编码字符集中的字符的整数。 字符编码在编码字符集的代码点和字节序列之间进行映射。一种编码字符集可能有一种或多种字符编码。例如,ASCII 有一种编码方案,而 Unicode 有多种编码方案 UTF-8、UTF-16、UTF_16BE、UTF_16LE 等。 JavaIO 在处理文本和文本文件时使用字符流 IO 类,Reader、Writer正如已经解释过的,Java 平台的默认字符集是 UTF-8,使用 Writer 类编写的文本以 UTF-8 编码,而 Reader 类以 UTF-8 读取文本。
使用 java.io 包,我们可以使用默认字符集编写和读取文本文件,如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 String str = "a Z â Δ 你 好 ಡ ತ ع" ;File file = new File ("x-utf8.txt" );try (BufferedWriter out = new BufferedWriter (new FileWriter (file))) { out.write(str); } try (BufferedReader in = new BufferedReader (new FileReader (file))) { String line; while ((line = in.readLine()) != null ) { System.out.println(line); } }
上面的示例直接使用使用默认字符集 (UTF-8) 的 char 流类 - Writer 和 Reader。
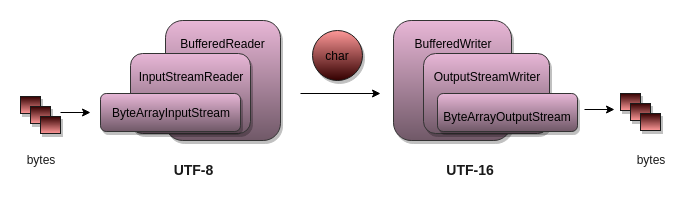
要以非默认字符集进行编码/解码,请使用面向字节的类,并使用桥接类将其转换为面向字符的类。例如,要以原始字节形式读取文件,请使用FileInputStream并将其包装InputStreamReader,这是一个可以将字节编码为指定字符集中的字符的桥。类似地,对于输出,使用OutputStreamWriter(桥)和FileOutputWriter(字节输出)
1 2 3 4 5 6 7 8 9 InputStream byteInStream = new FileInputStream (file);Reader encodedCharStream = new InputStreamReader (byteInStream, StandardCharsets.UTF_16LE); OutputStream byteOutStream = new FileOutputStream (file);Writer decodedCharStream = new OutputStreamWriter (byteOutStream, StandardCharsets.UTF_16LE);
以下示例以 UTF_16BE 字符集写入文件并将其读回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 String str = "a Z â Δ 你 好 ಡ ತ ع" ;Charset charset = StandardCharsets.UTF_16BE;File file = new File ("x-utf16be.txt" );try (BufferedWriter out = new BufferedWriter ( new OutputStreamWriter (new FileOutputStream (file), charset))) { out.write(str); } try (BufferedReader in = new BufferedReader ( new InputStreamReader (new FileInputStream (file), charset))) { String line; while ((line = in.readLine()) != null ) { System.out.println(line); } }
其实 Unicode 中除了 4 位编码外,CJK 还有 5 位码位的字符:
CJK Unified Ideographs Extension A (U+3400 through U+4DBF)
CJK Unified Ideographs (U+4E00 through U+9FFF)
CJK Compatibility Ideographs (U+F900 through U+FAD9)
CJK Unified Ideographs Extension B (U+20000 through U+2A6DF)
CJK Unified Ideographs Extension C (U+2A700 through U+2B739)
CJK Unified Ideographs Extension D (U+2B740 through U+2B81D)
CJK Unified Ideographs Extension E (U+2B820 through U+2CEA1)
CJK Unified Ideographs Extension F (U+2CEB0 through U+2EBE0)
CJK Unified Ideographs Extension I (U+2EBF0 through U+2EE5D)
CJK Compatibility Ideographs Supplement (U+2F800 through U+2FA1D)
CJK Unified Ideographs Extension G (U+30000 through U+3134A)
CJK Unified Ideographs Extension H (U+31350 through U+323AF)
文章的结尾有 java 代码实现了字符转内码以及内码转字符 的方法。
转码 转码是从一种编码到另一种编码转换,例如 UTF-8 到 UTF-16。我们经常遇到视频、音频和图像文件的转码,但很少遇到文本文件的转码。
想象一下,我们通过网络接收到以 CP-1252 (Windows-1252) 或 ISO-8859-1 编码的字节流,并希望将其保存到 UTF 8 的文本文件中。
有几个选项可以将一种字符集转码为另一种字符集。将其转码为使用 String 类的最简单方法。
1 2 String str = new String (bytes, StandardCharsets.ISO_8859_1);byte [] toBytes = str.getBytes(StandardCharsets.UTF_8);
虽然这相当快,但当我们处理大量字节时,它会受到影响,因为堆内存被分配给多个大字符串。更好的选择是使用 java.io 类,如下所示:
有关转码示例,请参阅Transcode.java ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 public class Transcode { private static long time; public static void main (String[] args) throws IOException { String str = new String ("aZâΔ你好ಡತع" ); Path path = Paths.get("x-utf16.txt" ); long fileSize = createBigFile(path, str, StandardCharsets.UTF_16, 1000 * 1000 ); byte [] bigArray = createBigArray(str, StandardCharsets.UTF_16, 1000 * 1000 ); markTime("start transcode" ); Path toPath = Paths.get("x-utf8.txt" ); transcodeFile(path, toPath, StandardCharsets.UTF_16, StandardCharsets.UTF_8); markTime(String.format("Java.IO, converted %s to %s size %d bytes" , path, toPath, fileSize)); byte [] convertedBytes = transcodeBytesAsString(bigArray, StandardCharsets.UTF_16, StandardCharsets.UTF_8); markTime(String.format("String encode and decode, converted %d bytes" , convertedBytes.length)); convertedBytes = transcodeBytesAsStreams(bigArray, StandardCharsets.UTF_16, StandardCharsets.UTF_8); markTime(String.format("Java.IO encode and decode, converted %d bytes" , convertedBytes.length)); } private static void transcodeFile (Path srcFile, Path dstFile, Charset fromCs, Charset toCs) throws IOException { try (BufferedReader in = Files.newBufferedReader(srcFile, fromCs); BufferedWriter out = Files.newBufferedWriter(dstFile, toCs);) { char [] buf = new char [10 ]; int c; while ((c = in.read(buf)) > 0 ) { out.write(buf, 0 , c); } } } private static byte [] transcodeBytesAsString(byte [] bytes, Charset fromCs, Charset toCs) { String str = new String (bytes, fromCs); byte [] toBytes = str.getBytes(toCs); return toBytes; } private static byte [] transcodeBytesAsStreams(byte [] bytes, Charset fromCs, Charset toCs) throws IOException { ByteArrayOutputStream boa = new ByteArrayOutputStream (); try (Reader in = new BufferedReader ( new InputStreamReader (new ByteArrayInputStream (bytes), fromCs)); Writer out = new BufferedWriter (new OutputStreamWriter (boa, toCs))) { char [] buf = new char [20 ]; int c; while ((c = in.read(buf)) > 0 ) { out.write(buf, 0 , c); } } return boa.toByteArray(); } private static long createBigFile (Path path, String str, Charset charset, int repeat) throws IOException { try (Writer out = Files.newBufferedWriter(path, charset)) { for (int i = 0 ; i < repeat; i++) { out.write(str); } } return Files.size(path); } public static byte [] createBigArray(String str, Charset charset, int repeat) throws IOException { byte [] bytes = str.getBytes(charset); ByteArrayOutputStream out = new ByteArrayOutputStream (); for (int c = 0 ; c < repeat; c++) { out.write(bytes); } return out.toByteArray(); } private static void markTime (String msg) { if (time == 0 ) { System.out.println(msg); time = System.currentTimeMillis(); } else { long eTime = System.currentTimeMillis(); System.out.printf("%s: %d ms %n" , msg, (eTime - time)); time = eTime; } } }
在 Linux 终端中使用 Unicode 我们可以通过一些简单的命令在 Linux 终端中处理文本编码。请注意,Linux 终端可以显示 ASCII 和 UTF-8 文件,但不能显示 UTF-16。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 $ echo -n -e '\xce\x94' > delta-8.txt $ echo -n -e '\xfe\xff\x03\x94' > delta-16.txt $ echo -n -e '\xe4\xbd\xa0\x20\xe5\xa5\xbd' > nihou-8.txt $ echo -n -e '\xfe\xff\x4f\x60\xfe\xff\x20\x59\x7d' > nihou-16.txt $ hd nihou-16.txt 00000000 fe ff 4f 60 fe ff 20 59 7d |..O`.. Y}| 00000009 $ file -i *.txt delta-16.txt: text/plain; charset=utf-16be delta-8.txt: text/plain; charset=utf-8 nihou-16.txt: text/plain; charset=utf-16be nihou-8.txt: text/plain; charset=utf-8 $ iconv -f UTF8 -t UTF16LE < nihou-8.txt > nihou-16le.txt $ iconv -l $ gedit nihou-8.txt $ gedit --encoding UTF-16LE nihou-16le.txt
汉字内码互转的实现 在这里我给一个字符串与内码互相转换的方法,可以拿来直接使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import org.apache.commons.lang3.StringUtils;public class CharacterUtil { public static String stringToCodePoints (String str) { StringBuilder stringBuilder = new StringBuilder (); str.codePoints().forEach(cp -> stringBuilder.append("\\u" ).append(Integer.toHexString(cp))); return stringBuilder.toString(); } public static String codePointsToString (String codePoints) { StringBuilder stringBuilder = new StringBuilder (); for (String hexCodePoint : codePoints.split("\\\\u" )){ if (StringUtils.isNotBlank(hexCodePoint)) { stringBuilder.append(codePointToString(Integer.parseInt(hexCodePoint, 16 ))); } } return stringBuilder.toString(); } public static String codePointToString (int cp) { StringBuilder sb = new StringBuilder (); if (Character.isBmpCodePoint(cp)) { sb.append((char ) cp); } else if (Character.isValidCodePoint(cp)) { sb.append(Character.highSurrogate(cp)); sb.append(Character.lowSurrogate(cp)); } else { sb.append('?' ); } return sb.toString(); } public static int length (String str) { return str.codePointCount(0 , str.length()); } }